Cache-Control headers to /liquidity and /prices endpoints
for potential faster retrieval in ALGA app./assets/0x...First of all: Happy New Year.
Changes:
GET /prices endpoint in that
e.g. the request's resolution and currency can be adjusted accordingly.ocean-protocol. We fixed the issue./blog/2021-11-15/marketing-week.currency=ocean-protocol.resolution=1d and resolution=1h options./ root endpoint was down as crawler produced faulty result which lead to a
crash in the chart generation.Through parallelization, we've now managed to speed up the entire crawl from a total run time of 18 minutes to only 58 seconds. In simpler terms, this means that the entire rugpullindex data base including all pricing records can now get updated in under a minute.
This is the achievement I've been waiting for to increase crawling frequency from daily to e.g. hourly. But more on that another time.
If you're using RPI to automate anything, please consider that from today on our crawler stability may be worse over the next few days as we've done a lot of changes. Fingers crossed that it all works well!
Here are the recent updates:
Authorization header validation in APII finally managed to implement a minimal user system to handle more than one user for the API. I've now sent out two additional keys to community members that asked for API access. If you, too, are interested in using the API, please shot us a message on Discord or email.
deposit and withdraw functionsStateTree library for handling state transitions
using a Merkle tree.The crawler failed tonight due to a potentially invalid assumption of mine. Both the BDP marketplace as well as OCEAN's instance of Acquarius returned data for "VORSTA-2", when in my view only Big Data Protocol's instance should have returned anything as the data set was launched there.
I addressed the problem in a workaround and filled an issue over on the Ocean Protocol GitHub.
Finally, regarding the calculation of VORSTA-2's gini index, it's easy to see that its composition of liquidity providers shouldn't yield such a positive gini index of < 0.7 as it does today. If we look at its balances, they're roughly equivalent to:
a: 1000
b: 1
c: 1
I haven't had time to look into the math of why its such a positive gini index, but I'm guessing that it has to do with the the small amount of LPs. In the upcoming days, it's likely that I'll, hence, increase the minimum amount of LPs a data set pool needs to have (e.g. 5). I'll also look into how I can make the gini index calculation favor popular pools over less populated ones.
/ has max-width: 70rem while
other pages have max-width: 50rem.<footer> in all pages./about page and introduce /faq page./api/v1/indices/OP-COMPOSITE-V1/ranks/ was failing the
daily integration tests. It's fixed. Starting to improve API tests
structurally now.GET /indices/OP-COMPOSITE-V1/ranks/:did failed integration
tests and is working again.This is a backend change that you won't notice on the website currently.
Cache-Control headers for all static assetsLast week, Kevin from datapeek.org asked me to do an interview with him. As I found the idea fun, I said yes and we had an email-based chat. The interview ended up being mostly about rug pull index and how I ended up working on it. It was my first time ever being interviewed. And what can I say; I enjoyed being in the limelight for once!
You can read it here.
That's all for this week. I'm wishing you a nice weekend. And hoping for myself that the crawlers stay online this time around.
Best, Tim
When you garden plants, sometimes just a little trimming of one or two leaves or branches is required to allow the plant to grow further. Today, after having a call with one of my users, I felt the need for trimming.
I updated to the latest version of classless.de, my CSS framework, and I rearranged the front page to show the information more quickly. Just a while back I read an essay called "Speed is the Killer feature". Today, I feel like it reflects my principles for building web apps well.
I hope you like the updated front page.
Best, Tim
Good morning,
oh how I wish to have a solution to the crawler problem that rugpullindex.com is currently experiencing! As I said, I've switched from Ethplorer to Covalent recently, as I had experienced a bug with Ethplorer. Well, now it turns out that Covalent is less reliable than Ethplorer. In fact, Ethplorer came back with a bug fix recently.
So since it seems that I shouldn't rely on neither of them 100%, I'm now changing the code to use them both. Distributing my risks. Dogfooding my own mantras. If one fails, I'll just use the other. Hopefully that'll solve the problem for good.
That's all for now. Planning to do some further updates this week.
Best, Tim
Tonight, the crawler broke when our service provider Covalent returned a non-JSON response. I fixed it by now catching that error and by re-starting the crawl.
Good morning,
this whole deal with the service provider is turning into a bit of a disaster. Since tonight, it's returning a 400 error for even more assets. I've received a response to my email that I sent to support. "We will investigate the issue and fix it in the case of a bug.", they told me on Thursday.
For me, the whole thing is starting to frustrate me. I knew the risk of being dependent on a third-party service provider. And, I already had plans for my own crawler in place. I feel I'm quite unlucky that this is happening now. But it's not in my control and so I'm currently trying to fix the problem in another way.
I've thought about building a crawler myself now. But I don't think I'll be quick enough. Maybe, there's other providers with similar functionality that I could use.
I'll keep you updated.
I researched online and found a similar provider. I can't speak to its reliability either, but using it addresses the problem for now. I've deleted the crawl of tonight and re-crawled. The website now displays the correct ranking again. The issue is resolved.
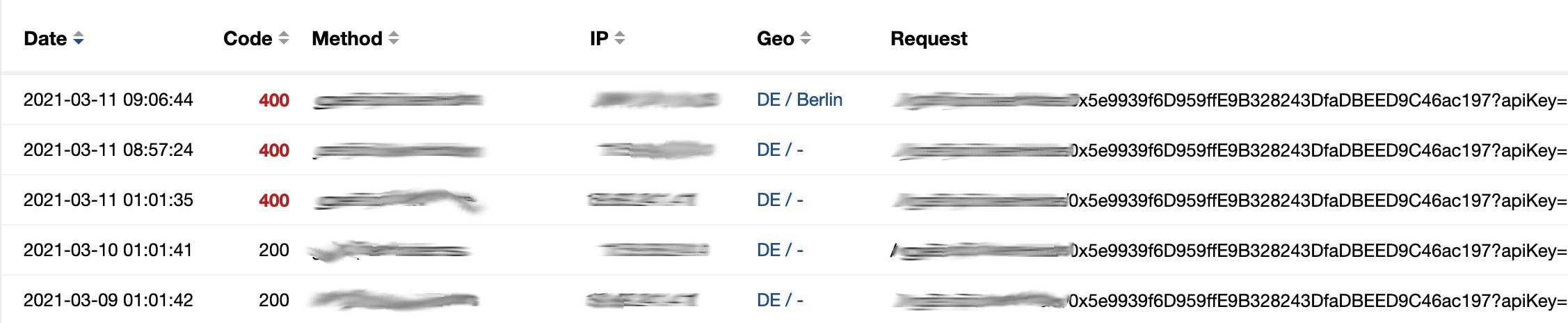
Tonight the crawler threw an error when retrieving the top holders of
0x5e9939f6D959ffE9B328243DfaDBEED9C46ac197 (token: EXCANE-93). Below is an
image of the API service's logs.
You can see that the request stopped working tonight and instead threw a 400 error. For now, I've added an exception route that allows the crawler to continue when receiving such an error.
I've reached out to the service's support too. For the time being though it's likely that EXCANE-93's information is displayed incorrectly. I'll keep you updated.
# :)/As announced on Feb 12, 2021, liquidity and price are now displayed in EUR. However, EUR values are not yet used within the ranking algorithm.
Midnight: After months, I made some changes to the crawler again which lead the page to be down the last two nights. The reason was a bug in the price crawler.
I was trying to get OCEAN's current EUR price and I was using Coingecko's historical API, that didn't send back any results (because it's "historical" and not "present" time). The crawler is now using Coingecko's simple API to get the price.
A few reflections on what I learned by having to open my laptop before breakfast and before going to bed on a Saturday:
Working on a website that always displays new information is fun. I check rugpullindex.com myself daily. I like the feeling of gardening the website. But soon I want to find ways to improve upon the above mentioned issues. It may just be a matter of improving the crawler's tests.
Best, Tim
Today marks an important day in the life of rugpullindex.com and OCEAN. When I was trying to compartmentalize the crawler's myriad subqueries, I noticed that, as intended, all data sets are normalized based on the all-time highest liquidity a data set pool reached.
What I had neglected was that I used OCEAN as the unit of liquidity. It makes no sense, though, as the goal is to compare any data set relative to the all-time best performing data set. With a fluctuating token, however, this may not work well.
Consider the data set QUICRA-0 that had 499,296 OCEAN in its pool yesterday—assuming that OCEAN/EUR traded at 0.5 EUR yesterday, QUICRA-0 had roughly 250,000 EUR liquidity in its pool. Now, consider that today the price of OCEAN increased by another 0.5 EUR to 1 EUR. But no change has occurred in QUICRA-0's liquidity pool. It means that while the number of OCEANs backing QUICRA-0 didn't change, its performance increased as the price of OCEAN doubled. Compared to yesterday QUICRA-0 is doing 2x as good!
Hence, I plan to measure a data set's liquidity now in fiat or specifically EUR. I've already finished the adjustment of the crawler. I wasn't able to finish integrating the change into the UI. But once the update is live, I'll inform you about it in detail.
Best, Tim
👋 Today marks the first day that I'm "getting paid" for working on rugpullindex.com. It's because I came in seventh place in OceanDAO's round 2 of grant proposals and was rewarded 10k OCEAN. My original plan was to use the DAO's grant as a freelance budget to work on rugpullindex.com properly. Hence, I swapped them to USDC.
Having a stable supply of digital currency now means I can "invoice" rugpullindex for the work I'm doing. It's really just a fancy way of doing accounting. There's no official company or anything. Still, it's a big step as it means that I'm now able to justify spending time on the project during "my working hours."
And it shows because I've been already working on it for a day. I've expanded the navigation and slimmed down the landing page. I've done it to get better results on PageSpeed Insights and make rugpullindex.com perform better in search engine results. As a result, there's now an about page and this blog. I'm planning to deprecate the old /changelog.txt.
Another SEO-thing I've done is that I've added a /sitemap.xml for crawlers. I'm tracking the website's performance on Google's Search Console now too. My plan is to make the website more informative over time.
And that's all I've to say for today. I hope you like the changes. And I also wanted to thank everyone that voted for me in the OceanDAO too. Thanks!
Hoping to see you around here soon again.
Best, Tim
Wow, it's been a while since I wrote something here. Still, I was busy thinking about next steps for rugpullindex.com. Mainly, about receiving funding to being able to continue the project.
And, indeed, I'm recognizing a promising opportunity ahead with Ocean Protocol's "OceanDAO" [1] having its second grants funding round on Feb 1, 2021. On Monday, it lead me to write a first draft for a grants proposal [2]. OceanDAO recommends submitting an "Expected ROI calculation" in the grants proposal to make voters understand the potential and future returns of the project[5]. However, it turned out, that DeFi Pulse Index isn't able to capture a significant market share within the DeFi ecosystem (0.03% or $55M). When applying the percentage to rugpullindex, the prospect became even bleaker as 0.03% of $600k would only amount to $183 of market capture for rugpullindex.com
Even though, it did disappoint me that the math wasn't working it, I'm still bullish as ever towards the project. Especially, as I recently read in one of Matt Lavine's "Money Stuff" newsletter posts, that tradiitonal index funds can become huge anti trust problems as soon as they start to hold majority shares in certain market segments [3]. When, for example, the S&P500 is suddenly capable of voting on board decisions of FAANG (Facebook, Amazon, Apple, Netflix, Google), I think it's no surprise that they wouldn't incite any of those companies against each other. After all, that could lead to a decrease in the index's value.
To me, that truly sounds like an antiquated problem. Technology allows the sensing of a crowds opinion already. Within blockchain, such governance scenarios have long been a topic of discussion. Actually, they work today [4]. And that's why I think that building indexes on blockchains is a cool problem that can address real-life problems.
In conclusion, I would like to say that I'm still eager to continue development here. I hope to receive a grant. So if you're reading this, make sure to vote!
That's all. Have a nice day.
To increase virality of the service, I've decided that I want to have some type of badge for a data set provider. I ended up using shields.io. By visiting the FAQ, you can now add a badge for your own data set. It's a beta features that I haven't testet too much. So I'm curious on how it goes.
Released the rugpullindex.com launch blog post on my personal website: https://timdaub.github.io/2020/12/11/rugpullindex/
It got lots of attention which made me happy. Lots of people have reached out since then.
This morning, when I had my coffee in the park, I thought again about what I wrote last week regarding the inclusion of liquidity into my risk model. I'm specifically referring to the changelog.txt entry on the 30/11/2020, where I proposed to use the absolute currency value of liquidity within a pool to multiply it with the Gini score.
Thinking about it again, I realized that I don't like the approach I proposed then anymore. The reason being, that by using e.g. the EURO value of a pool's liquidity in a multiplication seems fairly arbitrary. Why e.g.
After all, the Gini score and each market's liqudity are independently-provisioned quality measurements. Hence, this morning, I started thinking about how to improve what I proposed last week.
I believe that a relative quality measure that is a combination of liquidity and equality distribution is still useful for investors. I think it should not be denoted in a commonly known unit, unless is makes a specific quality statement about it.
For example, in the future, I could imagine a quality measure called "Safe liqudity" that is denoted in OCEAN, EUR or USD and that gives information about the absolute amount of liqudity that is safely distributed within a pool.
However, for now I'm not interested in that measure. Instead, I'd like to use a comprehensive and relative measure of liqudity over all markets as a measure of an indivdual pool's liquidity. Actually, my friend Jost Arndt proposed a simple algorithm to find a relative measure for all pools' liquidity:
His argument was that now, since all pools' liquidity is within the bountries of , this measure could be used to find an overall score s to rank all data sets:
The properties of this model are great because:
However, I'm not only a fan of the algorithms properties. From the get-go of this project, I've been convinced that a simple measure is key for the meaningfulness and utility of the index. I believe that the above formula passes those criteria. Hence, for the upcoming weeks, I'm planning to integrate it into the website.
And that's all for today's thoughts on rugpullindex.com. If you've found this entry useful or have feedback, feel free to reach out via [email protected]
Best, Tim
The root endpoint / now includes a "Cache-Control" header with a maxAge
around the time of rugpullindex.com's daily crawl. This means that a user's
browser is now caching the site. But additionally this allows a CDN or reverse
proxy to cache the site too. For now, I've configured my reverse proxy to
cache according to "Cache-Control" headers which speed up page loads
significantly. Since for most of the day, statically-cached content is served
up now, this should allow handling lots of traffic too.
Currently, I'm still thinking a lot about rugpullindex.com and how to grow its audience. I believe that in the future, it will be really important to be able to automatically filter and sort blockchain-based markets on some sort of metric, similar to how the Web is sorted by algorithms today (social media algorithms, Google's page-rank, etc.).
In terms of improving the site in the short term, I'm hence driven to do two things in particular:
Regarding (1), improving the scoring method, I already had a particular idea that I'd like to motivate briefly.
Most decentralized exchanges using automated market makers currently use liquidity to measure a pool's overall performance. However, as we've discussed already, this ignores the fact that distinct liquidity can have distinct quality. As we've assumed from the beginning, the distribution of liqudity shares within the pool can be used as a qualitative metric. Some examples:
Hence, instead of sorting the index only by a pool's liquidity distribution, I'm now thinking of using the score as a weight on the pool's liquidity:
For a pool like TREPEL-36, this would mean the following (values from today): At a score of 0.69 and a total liquidity of 40900.54€, its new score is:
whereas for TASLOB-45, having a score of 0.88 with a total liquidity of 224665.20€, it meant:
This change, as can be seen above, would then favor large pools over small ones, while still being significantly biased towards an equal distribution of shares.
If you've made it so far: Thanks for reading! And if you have feedback on this idea, feel free to contact me! My email is [email protected]
That's all for today.
Best, Tim