Countless times throughout maintaining this document, I've worried about the sustainability of our project. I said that I'd like to diversify income streams and that generally, we're struggling to understand where we should be extracting value. We've talked to many potential customers and people interested in our project - some that understood what we were doing and some that didn't get it at all.
Today, I'd like to proudly say that I think we have found the strongest rationale for continuing the project so far. But first, the context:
Already in December 2020, I decided to add badges to rugpullindex.com that'd allow a data publisher to include their rank in the description on the Ocean Protocol marketplace. Here's how that badge looks:
And here is its code:
[](https://rugpullindex.com)
As you can see, the badge is making use of the RPI API by requesting a data
set's current rank in the url query string parameter:
url=https://rugpullindex.com/api/v1/indices/OP-COMPOSITE-V1/ranks/did:op:7Bce67697eD2858d0683c631DdE7Af823b7eea38;
In this case, it's requesting the rank for DataUnion's QUICRA-0.
I had long forgotten about this feature myself, and indeed, months ago, we even decided to de-prioritize the FAQ page including the badge manual.
But then, days ago I remembereed reading Brian Schrader's "Why All My Servers
Have An 8GB Empty
File"
article and ended up anxiously dfing around the RPI backend server to make
sure we still had enough storage space available. And when I did that, I
discovered something.
ls -ahl /root/.pm2/logs/
total 1.6G
drwxr-xr-x 2 root root 4.0K Nov 18 2020 .
drwxr-xr-x 5 root root 4.0K Apr 8 2021 ..
-rw-r--r-- 1 root root 26K Aug 29 02:01 crawler-error.log
-rw-r--r-- 1 root root 27M Nov 2 01:02 crawler-out.log
-rw-r--r-- 1 root root 35M Nov 2 13:45 rugpullindex.com-error.log
-rw-r--r-- 1 root root 1.5G Nov 2 13:45 rugpullindex.com-out.log
I found that since last year, we had logged every single request to our website in a text file for debugging purposes. A whopping 1.5GB of logs that contained everything from when users had requested specific information about a data set and to all API usages.
Then it hit me: "The server must have also logged all requests from shields.io.", meaning that there was a chance we had real data about the Ocean Protocol marketplace website visitors.
Given that I had just recently called to rationalize the ROI calculations in the OceanDAO, these numbers struck me as immensely important. My immediate thoughts were that we'd now finally be able to understand our website's impact on the global web3 data market.
And indeed, that's what I managed to conclude today. In the following passages, you'll find a shallow evaluation of our data and what it means for the continued existence of our product.
We've open sourced all of it in a Google Sheet and we're curious to see if the community can extract further findings.
Inspecting the data, you'll see that only a handful of data publishers had included the badge; those being: INVBAR-10, INCSQU-53, EXCANE-93, QUICRA-0 (only for a limited amount of time). The biggest contributor is EXCANE-93.
We can plot all shields.io requests vs time in a graph:
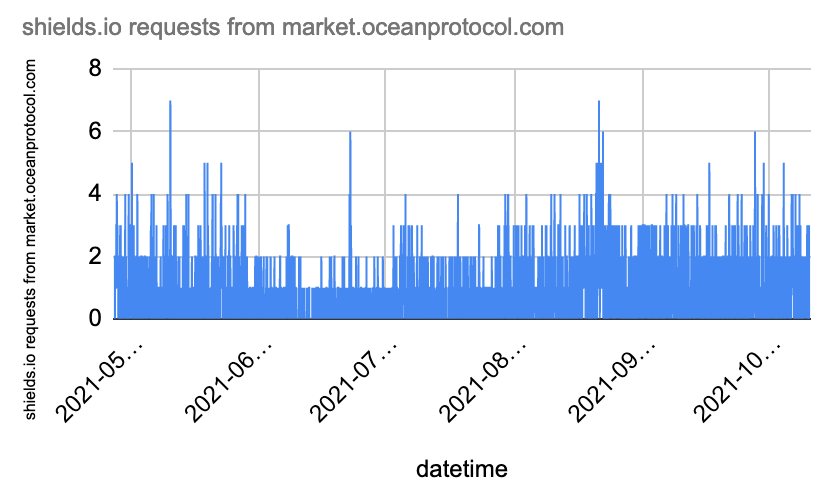
With this, I think we can already classify the popularity of market.oceanprotocol.com website relatively to others. E.g. we have additional data from plausible.io/rugpullindex.com and plausible.io/oceanpearl.io.
Given that EXACANE-93 is in third place for the most liquid asset ("Highest Liquidity") on the OP marketplace front page, we could start speculating about its total daily visitors, assuming a rough bounce rate.
But, at the time, that didn't seem useful to me. I wanted to understand if rugpullindex.com had an impact on the view count of the Ocean Protocol marketplace. And given that the shields.io data set was independently collected from the web analytics we gather with plausible, I figured some statistical math could yield insights.
By normalizing all data to an hourly resolution, I ended up being able to calculate a Pearson correlation between the rugpullindex.com hourly visitors and the shields.io requests arriving at our end. I was disappointed to see that they were only connected by 0.07 and was about to call it a day. But then I remembered that on plausible.io, we had also collected all outbound clicks since April 2021.
See, when you visit our website, and click away from our domain, then plausible.io will record this as an "Outbound Click" event and log the specific path you left towards.
Looking at the yearly outbound clicks stats, I was quick to determine that only 14 outbound clicks towards EXACANE-93 had happened. I, hence, concluded that just correlating the shields.io data set and the visitors from RPI might not cut it. It may not show the full picture.
And so, I ended up downloading the high-res version of the outbound click data set from plausible. My thoughts were that we could additionally model market.oceanprotocol.com's visitor stats by assuming that each outbound click towards them also meant an active visitor on their site.
So I downloaded the data and plotted it too:
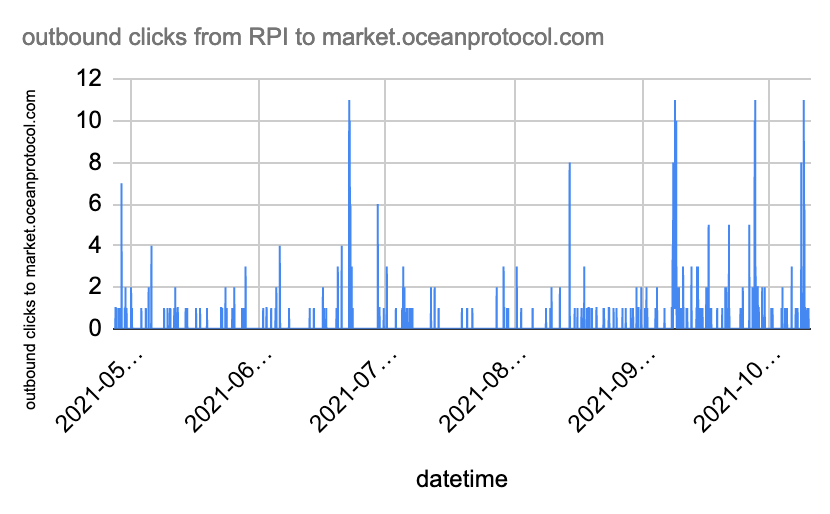
We can see that it's much sparser. Initially, I was like: "OK, now that we have two independent data sets: Why don't we just assume that their addition is the total amount of hourly visitors to the Ocean Protocol marketplace."
I created another column and called it "Inferred OP marketplace visitors." For each row, it adds the outbound clicks and the shield.io requests for a "fuller" distribution of the simulated Ocean marketplace website visitor data set. Here's it plotted too:
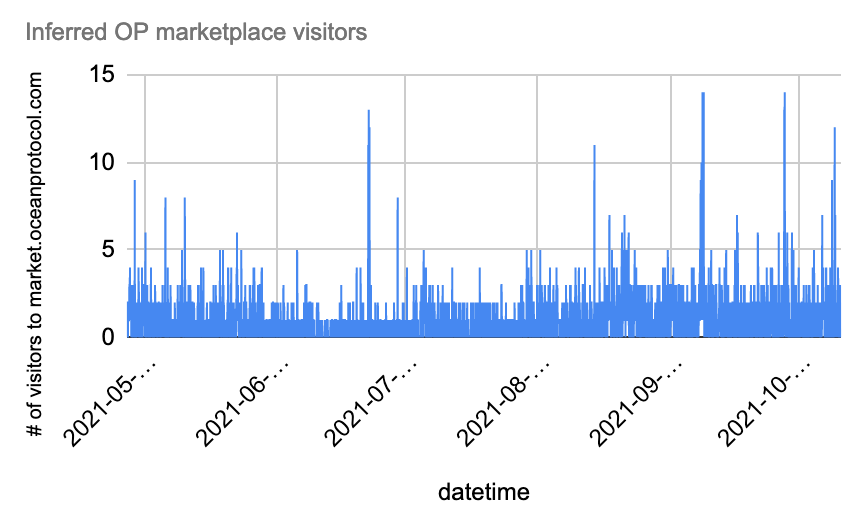
I was happy as it ended up looking much better, and so, logically, I then continued by trying to extract the hourly visitors to rugpullindex.com's main page "/". The next graph gives an overview of that:
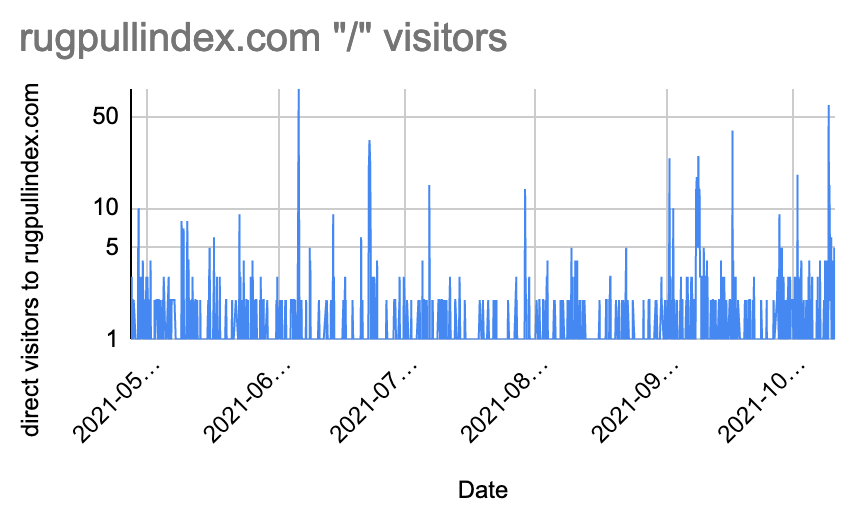
Lastly, I wanted to find out how strongly Ocean Protocol's marketplace and rugpullindex.com visitors are connected. I calculated a Pearson correlation between rugpullindex.com's "/" root site visitors and the inferred Ocean Protocol marketplace visitor data set.
I found that it correlates by roughly 0.4. At 4000 samples (we're logging since the end of April), and a significance level of 0.05, this correlation ends up being a significant finding.
The P-Value is < .00001. The result is significant at p < .05.
Now, to understand if RPI independently contributed to the above-stated amount of visitors to the Ocean Marketplace, for completeness, we'd probably have to repeat the process with an additional control website. That is, in academia, we'd have to do that.
But I ain't no scientist and what I see here is good enough. 0.4 isn't the best correlation ever, but considering that we're dealing with noisy distributions and mostly an assumed visitor model - I'm pretty happy about our findings.
I'm also convinced that this kind of data-driven practice ought to be the default method for OceanDAO projects to create a fundraising rationale (or ROI calculation). I don't want to stop here: We already have plans to extend this modeling for the next round. Simply because all data buying and consuming on the Ocean Protocol marketplace takes place on-chain and is, hence, potentially useful for us too.
Imagine if we could correlate website visitors to on-chain new-money transactions! That'd be something, I think would, product-offering-wise, not only be interesting for us - but also others. It'd be Google Analytics but with blockchain insights.
But those things are future stuff and we've pledged to be present in the presence. So for all OCEAN holders reading this, I'd like to ask for your votes and attention in OceanDAO round 11. If you like our product, website, blog and Discord, please consider voting for us. And thanks for reading.
Best, Tim