Hi there,
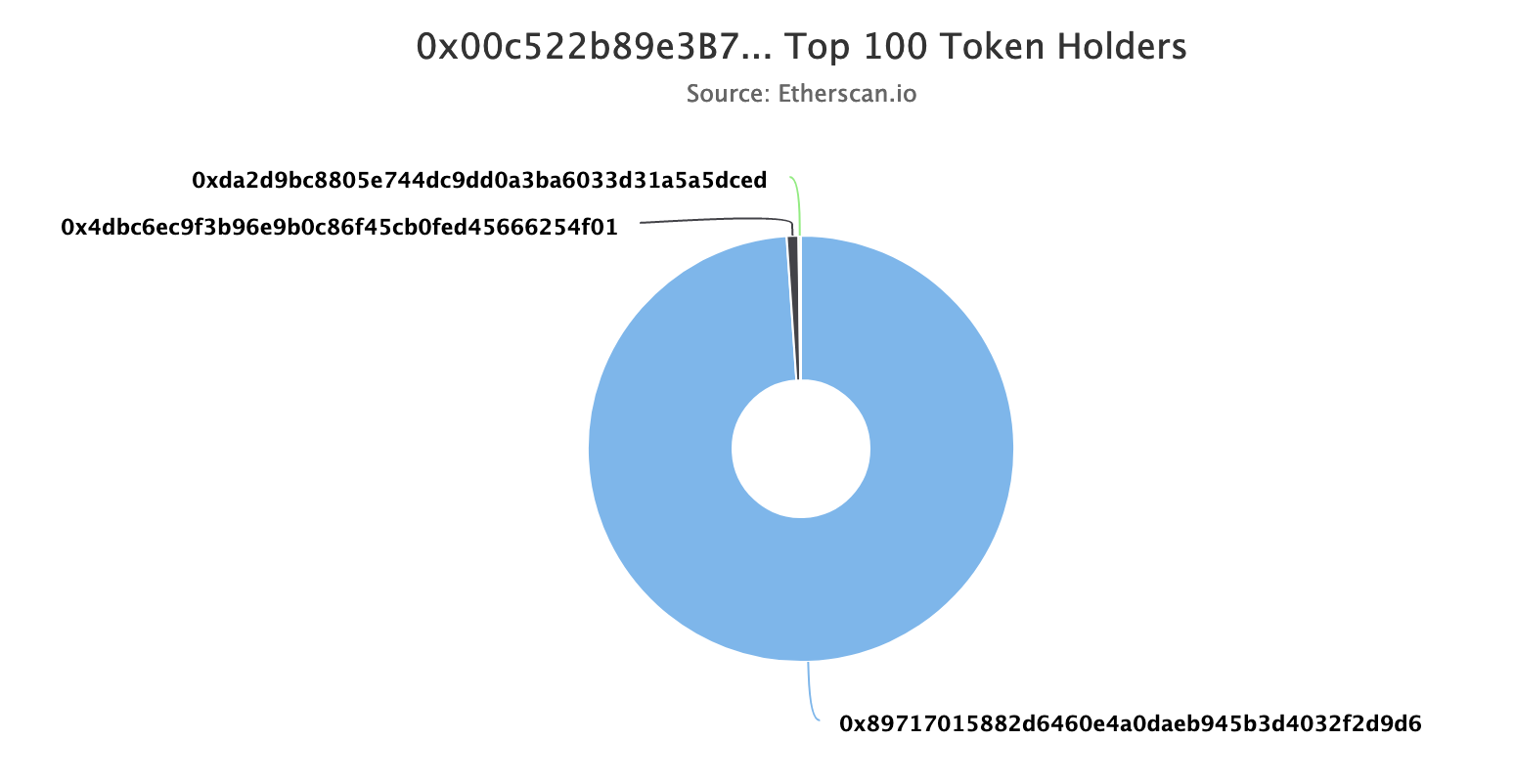
I mentioned in my last entry that the gini coefficient seemed too positive for some data sets. In particular I talked about VORSTA-2 and how was able to enter in rank #3 with only 3 token holders, the richest one owning 98% of its pool. Below is a picture of VORSTA-2's share distribution. I don't think there's a lot of math needed to understand that this pool has no equal distribution of liquidity.
When I implemented the gini coefficient score at the end of last year, I defaulted to a formula from Wikipedia that uses the income distribution of a population and a relative mean for the incomes' absolute differences (see below).
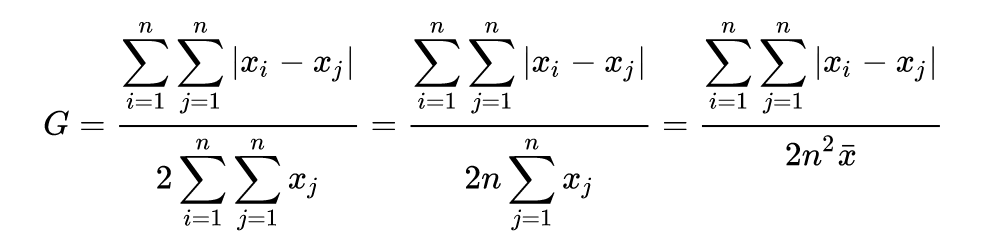
Essentially, it compares each LP's stake in the pool and then divides (roughly) by the mean stake. For VORSTA-2 (and similar ones), the formula allowed it to rank highly on rugpullindex.com as any small share in the pool counted. For VORSTA-2, 0xda2d9's stake (roughly $35) contributed as much to the calculation as the stake of 0x89717 ($12k).
Using pen and paper, I sat down to think about a solution. I think I found a simple one that I'd like to share now:
The new ranking went live before this blog post. You can check it out on the front page. In my opinion, the solution improves the ranking's results. Small sets with an apparently positive gini coefficient are filtered, while we're still giving data sets with a bigger community a fair chance.
Looking at the results, I found it curious how many data sets had "sneaked up" in the ranking over time. Obviously, I can't say anything about any publisher's intentions. It could have been that some moved some liquidity to improve their scores. It could have also just been regular liquditiy providing. It could have been chance.
In any case, however, I'm now motivated to further improve the gini coefficient's safety by tracking data that's capital-inefficient to manipulate. I already have some ideas. Until then, feel free to continue playing mouse if you dare :)
Best, Tim
PS: Thanks so much for voting in OceanDAO's Round 6!